自定义算子
概述
在添加自定义算子前,请参阅算子列表,避免不必要的重复。
MNN 算子转换与实现结构
MNN 的算子转换与实现如下图,
模型转换包括以下步骤,二选一:
训练框架导出的Op与MNN的Op一一对应:前端直接转换
用组合器(参考 tools/converter/source/optimizer/onnxextra 等目录)由 MNN 算子组合。
MNN 算子实现包括如下步骤
添加Schema描述(必须)
添加维度计算(若算子输出维度和输入一致可跳过)
添加几何计算实现(可选,如果实现几何计算,无须后续在各后端添加算子实现)
添加各后端算子实现(可选,选择需要部分进行实现)
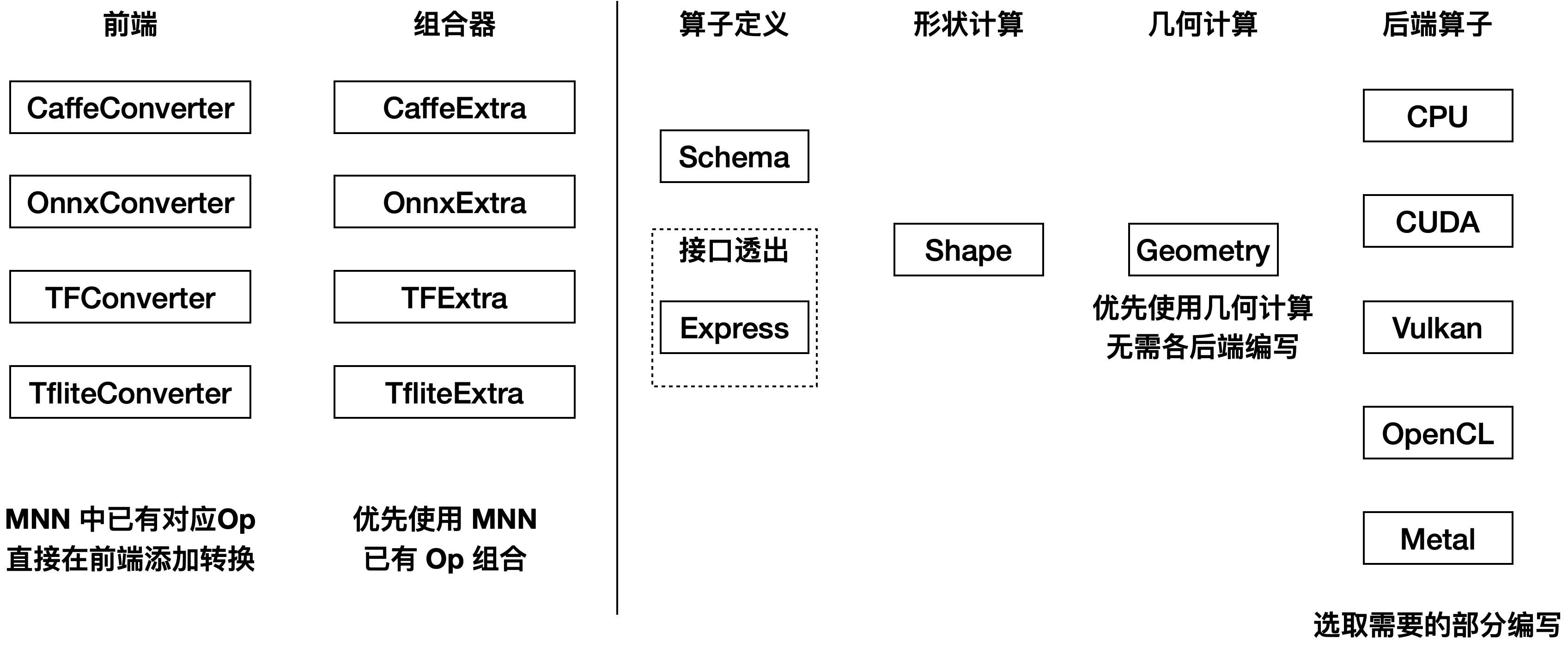 image.png
image.png
添加算子的流程
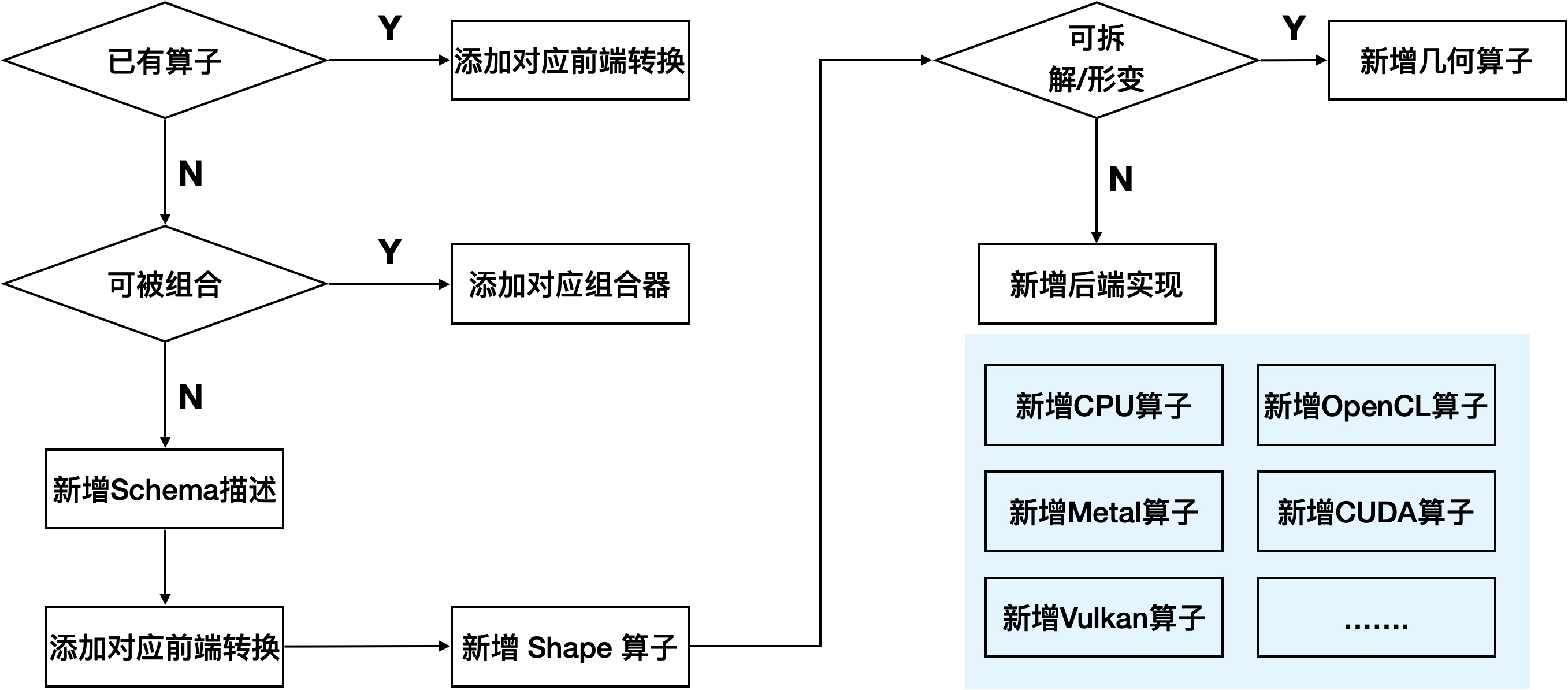 image.png
简单来说,优先转换,然后组合,然后几何计算,最后各后端实现。
image.png
简单来说,优先转换,然后组合,然后几何计算,最后各后端实现。
添加Schema描述
若添加的算子不在MNN的算子列表中,需要添加模型描述。修改完模型描述后,需要调用generate脚本重新生成模型描述头文件。
添加算子类型
在schema/default/MNN.fbs文件的OpType列表里追加算子名称,如:
enum OpType : int {
AbsVal,
QuantizedAdd,
...
MyCustomOp
}
添加算子参数描述
如果算子不包含参数,则可以略过这一步。
首先,在schema/default/MNN.fbs文件的OpParameter列表里追加算子参数名称,如:
union OpParameter {
QuantizedAdd,
ArgMax,
AsString,
...
MyCustomOpParam
}
而后,添加参数描述。如果算子来自Caffe,选择CaffeOps.fbs;如果算子来自TensorFlow,就使用TensorflowOp.fbs。
table MyCustomOpParam {
padX:int;
padY:int;
kernelX:int;
kernelY:int;
strideX:int;
strideY:int;
dataType:DataType=DT_FLOAT;
}
添加模型转换
用户可根据自己使用的框架,选择对应的模型转换模块去添加算子转换的支持。添加完模型转换后,需要重新cmake。
目前,MNN支持TensorFlow、TensorFlow Lite、Caffe、ONNX和TorchScript模型格式的转换。
TensorFlow模型转换
添加转换类 在
tools/converter/source/tensorflow下添加MyCustomOpTf.cpp。可以直接声明转换类,也可以利用宏定义简化代码。
直接声明示例:
class MyCustomOpTf : public tfOpConverter {
public:
virtual void run(MNN::OpT *dstOp, TmpNode *srcNode, TmpGraph *tempGraph);
MyCustomOpTf() {}
virtual ~MyCustomOpTf() {}
virtual MNN::OpType opType();
virtual MNN::OpParameter type();
}
等效宏定义示例:
DECLARE_OP_CONVERTER(MyCustomOpTf);
需要实现run、析构、opType和type函数。其中,run函数用于解析模型的proto文件得到参数,然后赋值给flatbuffer自定义参数。参数srcNode保存有输入输出节点信息,可以根据输入输出节点在tempGraph中找到TmpNode。调用函数find_attr_value(const tensorflow::NodeDef& node, const char* key, tensorflow::AttrValue& value)获得对应参数的值。
注册转换类:
REGISTER_CONVERTER(MyCustomOpTf, MyCustomOp);
添加映射 在
OpMapper.hpp中添加相应的TensorFlow Op名字到MNN Op名字的映射:
{"OpName1", MNN::OpType_MyCustomOp},
{"OpName2", MNN::OpType_MyCustomOp},
处理Op附带的Const 如果Const不作为此Op的参数,而是看成一个单独的Op,可以忽略此步骤;如果Op要把Const当成参数,要在文件
TmpGraph.cpp里修改函数_genMinGraph(),把相应Const节点的isCovered属性设置为true。
TensorFlow Lite模型转换
添加转换类 在
tools/converter/source/tflite下添加MyCustomOpTflite.cpp。
宏定义示例:
DECLARE_OP_COVERTER(MyCustomOpTflite);
需要实现函数:
MyCustomOpTflite::opType(bool quantizedModel);
MyCustomOpTflite::type(bool quantizedModel);
MyCustomOpTflite::run(MNN::OpT *dstOp,
const std::unique_ptr<tflite::OperatorT> &tfliteOp,
const std::vector<std::unique_ptr<tflite::TensorT> > &tfliteTensors,
const std::vector<std::unique_ptr<tflite::BufferT> > &tfliteModelBuffer,
const std::vector<std::unique_ptr<tflite::OperatorCodeT> > &tfliteOpSet,
bool quantizedModel)
其中,run函数相比TensorFlow的版本,多一个quantizedModel参数。若qu``antizedModel为true,则模型为量化模型,需转为相应的量化Op;若为false,转为浮点Op。在run函数中需要设置输入、输出tensor的index:
// set input output index
dstOp->inputIndexes.resize(1);
dstOp->outputIndexes.resize(1);
dstOp->inputIndexes[0] = tfliteOp->inputs[0];
dstOp->outputIndexes[0] = tfliteOp->outputs[0];
注册转换类:
using namespace tflite;
REGISTER_CONVERTER(MyCustomOpTflite, BuiltinOperator_OPName);
Caffe模型转换
添加转换类 在
/tools/converter/source/caffe下添加MyCustomOp.cpp。
类声明示例:
class MyCustomOp : public OpConverter {
public:
virtual void run(MNN::OpT* dstOp,
const caffe::LayerParameter& parameters,
const caffe::LayerParameter& weight);
MyCustomOp() {}
virtual ~MyCustomOp() {}
virtual MNN::OpType opType();
virtual MNN::OpParameter type();
};
实现run、opType、type函数,在run函数中解析caffe参数得到具体参数。其中参数parameters保存有Op的参数信息,weight保存有卷积、BN等数据参数。
注册转换类:
static OpConverterRegister<MyCustomOp> a("MyCustomOp");
ONNX模型转换
添加转换类 在
/tools/converter/source/onnx下添加MyCustomOpOnnx.cpp。
类声明示例:
DECLARE_OP_CONVERTER(MyCustomOpOnnx);
需要实现函数:
MNN::OpType MyCustomOpOnnx::opType();
MNN::OpParameter MyCustomOpOnnx::type();
void MyCustomOpOnnx::run(MNN::OpT* dstOp,
const onnx::NodeProto* onnxNode,
std::vector<const onnx::TensorProto*> initializers);
run函数中,onnxNode即onnx原始节点信息,权重等数据信息需从initializers取。
注册转换类:
REGISTER_CONVERTER(MyCustomOpOnnx, MyCustomOp);
添加维度计算
如果该Op的输出Tensor大小与第1个输入Tensor一致,并且不需要分析FLOPS,可以跳过这步。添加完形状计算代码后,需要在根目录下运行 python3 tools/scripts/register.py,并重新cmake。
添加计算类
在/source/shape下添加ShapeMyCustomOp.cpp:
class MyCustomOpSizeComputer : public SizeComputer {
public:
virtual bool onComputeSize(const MNN::Op* op, const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) const override {
// set tensor->buffer.type
// .dimensions
// .dim[x].extent
// .dim[x].stride
// .dim[x].flag
return true;
}
virtual float onComputeFlops(const MNN::Op* op,
const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs) const {
return flops_for_calc_output_from_input;
}
};
在onComputeSize函数中,根据输入tensor的维度信息,计算输出tensor的维度信息,并设置输出tensor的数据类型。计算完成后返回true;若输入维度信息未知返回false。
在onComputeFlops函数中,根据输入、输出tensor的维度信息,返回总计算量。
注册计算类
REGISTER_SHAPE(MyCustomOpSizeComputer, OpType_MyCustomOp);
添加实现
添加完算子实现后,需要在根目录下运行 python3 tools/scripts/register.py,并重新cmake。
添加CPU实现
在source/backend/CPU目录下添加CPUMyCustomOp.hpp、CPUMyCustomOp.cpp。
1. 实现类声明
class CPUMyCustomOp : public Execution {
public:
// 若执行onExecute需要使用缓存,在此函数中申请,若无可不声明
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
// 具体的Op执行函数
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
2. 实现onResize和onExecute
在onResize中,调用backend()->onAcquireBuffer(&mCache, Backend::DYNAMIC)进行缓存的申请,调用backend()->onReleaseBuffer(&mCache, Backend::DYNAMIC)回收缓存。释放后的内存可以被复用。
在onExecute中,做必要的输入的检查,有利于提前发现问题。若执行完毕正确返回NO_ERROR。
3. 注册实现类
class CPUMyCustomOpCreator : public CPUBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs,
const MNN::Op *op,
Backend *backend) const override {
return new CPUMyCustomOp(backend);
}
};
REGISTER_CPU_OP_CREATOR(CPUMyCustomOpCreator, OpType_MyCustomOp);
添加Metal实现
添加Shader 在
source/backend/Metal目录下添加MetalMyCustomOp.metal,并添加进Xcode工程。metal可以参考目录下已有实现。
2. 实现类声明
在source/backend/Metal目录下添加MetalMyCustomOp.hpp和MetalMyCustomOp.cpp,并添加进Xcode工程:
class MetalMyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
3. 实现onResize和onExecute
不同于CPU Tensor将数据存储在host指针中,Metal数据指针存放在deviceId中,deviceId上存储的是id<MTLBuffer>:
auto buffer = (__bridge id<MTLBuffer>)(void *)tensor->deviceId();
Metal Op的特定参数等可以通过id<MTLBuffer>存储。buffer数据类型可以与tensor不同,buffer甚至可以混合多种数据类型,只需保证创建时指定了正确的长度即可。例如:
auto buffer = [context newDeviceBuffer:2 * sizeof(int) + 2 * sizeof(__fp16) access:CPUWriteOnly];
((__fp16 *)buffer.contents)[0] = mAlpha / mLocalSize; // alpha
((__fp16 *)buffer.contents)[1] = mBeta; // beta
((int *)buffer.contents)[1] = mLocalSize; // local size
((int *)buffer.contents)[2] = inputs[0]->channel(); // channel
在创建buffer时,需要指定访问控制权限。目前共有三种权限:
CPUReadWrite,数据在CPU/GPU间共享存储,一般用于device buffer;CPUWriteOnly,数据通过CPU写入后不再读取,一般用于参数buffer;CPUTransparent,数据只在GPU中,一般用于heap buffer;
MNNMetalContext在创建buffer上,有两套相近的接口,区别只在数据的生命周期上:
device占用的内存在单次推理过程中都不会被复用;
而heap占用的内存,在调用
-[MNNMetalContext releaseHeapBuffer:]之后,可以被其他Op复用;
一般而言,heap只会与CPUTransparent一起使用。heap实际只在iOS 10+上有效,iOS 9-上会回退到device上。
使用Metal时,如非特殊情况,禁止自行创建device和library。加载library、编译function都是耗时行为,MNNMetalContext上做了必要的缓存优化。通过context执行Metal的示例如下:
auto context = (__bridge MNNMetalContext *)backend->context();
auto kernel = /* metal kernel name NSString */;
auto encoder = [context encoder];
auto bandwidth = [context load:kernel encoder:encoder];
/* encoder set buffer(s)/sampler(s) */
[context dispatchEncoder:encoder
threads:{x, y, z}
maxThreadsPerGroup:maxThreadsPerThreadgroup]; // recommended way to dispatch
[encoder endEncoding];
4. 注册实现类
class MetalMyCustomOpCreator : public MetalBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs,
const MNN::Op *op, Backend *backend) const {
return new MetalMyCustomOp(backend);
}
};
REGISTER_METAL_OP_CREATOR(MetalMyCustomOpCreator, OpType_MyCustomOp);
添加注册代码后,重新运行一下 CMake ,自动变更注册文件
添加Vulkan实现
添加Shader 在
source/backend/vulkan/execution/glsl目录下添加具体的shader(*.comp)。若输入内存布局为NC4HW4,则按image实现,否则采用buffer实现。可以参考目录下已有实现。然后,执行makeshader.py脚本编译Shader。
2. 实现类声明
在目录source/backend/vulkan/execution/下添加VulkanMyCustomOp.hpp和VulkanMyCustomOp.cpp:
class VulkanMyCustomOp : public VulkanBasicExecution {
public:
VulkanMyCustomOp(const Op* op, Backend* bn);
virtual ~VulkanMyCustomOp();
ErrorCode onEncode(const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs,
const VulkanCommandPool::Buffer* cmdBuffer) override;
private:
// GPU Shader所需的参数
std::shared_ptr<VulkanBuffer> mConstBuffer;
// Pipeline
const VulkanPipeline* mPipeline;
// Layout Descriptor Set
std::shared_ptr<VulkanPipeline::DescriptorSet> mDescriptorSet;
};
实现 实现函数
onEncode,首先需要做内存布局检查:若为NC4HW4,则Shader用image实现,否则用buffer。执行完毕返回NO_ERROR。
4. 注册实现类
class VulkanMyCustomOpCreator : public VulkanBackend::Creator {
public:
virtual Execution* onCreate(const std::vector<Tensor*>& inputs,
const MNN::Op* op,
Backend* backend) const override {
return new VulkanMyCustomOp(op, backend);
}
};
static bool gResistor = []() {
VulkanBackend::addCreator(OpType_MyCustomOp, new VulkanMyCustomOpCreator);
return true;
}();
添加OpenCL实现
添加Kernel 在
source/backend/opencl/execution/cl目录添加具体的kernel(*.cl)。目前feature map均使用image2d实现。可以参考目录下已有实现。然后执行opencl_codegen.py来生成kernel映射。
2. 实现类声明
在目录source/backend/opencl/execution/下添加MyCustomOp.h和MyCustomOp.cpp:
template <typename T>
class MyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
实现 实现函数
onResize(可选)、onExecute。执行完毕返回NO_ERROR。
4. 注册实现类
OpenCLCreatorRegister<TypedCreator<MyCustomOp<cl_data_t>>> __my_custom_op(OpType_MyCustomOp);
添加OpenGL实现
添加Shader 在
source/backend/opengl/glsl下添加具体的shader(*.glsl),不用加文件头,feature map 均采用image3d表示。可以参考目录下已有实现。而后,在source/backend/opengl目录下执行makeshader.py。添加Executor 在
source/backend/opengl/execution/目录下添加GLMyCustomOp.h和GLMyCustomOp.cpp:
class GLMyCustomOp : public Execution {
public:
GLMyCustomOp(const std::vector<Tensor *> &inputs, const Op *op, Backend *bn);
virtual ~GLMyCustomOp();
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
private:
std::shared_ptr<GLProgram> mProgram;
};
实现 实现函数
onResize(可选)、onExecute。执行完毕返回NO_ERROR。
4. 注册实现类-
GLCreatorRegister<TypedCreator<GLMyCustomOp>> __my_custom_op(OpType_MyCustomOp);